
On Scaling's End
The end of pretraining scaling; chart crime; post-training boosts math and coding; economic risks; bubble talk

Scaling Laws
Recent progress in AI has been driven by scaling up different aspects of AI models. Scaling doesn't just mean making models bigger. You can scale data quality, data size, model size, training compute, and post-training methods.
Compute demand has outpaced improvements in chip performance - AI companies are hoarding chips faster than semiconductor fabricators are improving them. Frontier labs should be able to scale up compute at this rate until 2030, but after that we may run into problems due to bottlenecks in data, chip production, capital, and energy.1
This is assuming no geopolitical disruptions to the semiconductor supply chain. Semiconductor manufacturing is heavily concentrated in east Asia, although the US is making investments to move some back onshore. In particular, Taiwan, and more specifically the Taiwan Semiconductor Manufacturing Corporation (TSMC) manufacture the vast majority of advanced logic chips (i.e GPUs, TPUs, etc ) that are used to train AI systems. These chips are designed in America, mostly by NVIDIA, but also increasingly in house by Google, Meta, Microsoft and Amazon.2 Geopolitical tensions around Taiwan add a layer of uncertainty to AI's advancement.
Chart Crime and Punishment
At the start of the scaling era, sometime between 2017 (transformer paper) and 2019 (GPT2), people at OpenAI noticed you can reliably make transformer language models better and better without any algorithmic improvements by just giving them more data and parameters. It’s worth taking a minute to pause and note how extraordinary this is, and how much it went against conventional wisdom in AI at the time. The consensus among AI academics was that intelligence was very complicated - you couldn’t just get new capabilities in AI by throwing more data and compute at a model. If you wanted to build a better model, you needed algorithmic improvements - many of them. We were 20 big breakthroughs away from building AGI. All of a sudden, it looked like this wasn’t the case - maybe we could just keep scaling to real intelligence. 3
In the paper, they found that model error (or loss, L, as it is known in the industry) reliably decreased as you increase model parameter count, dataset size, or training compute. I think their equations are more intuitive if you rewrite them in terms of model performance Q, which we know is inversely proportional to model loss L.
This tells us that as you scale up your model in different ways, you get better performance, but it levels off.

This is empirically what we saw. For the first while, performance gains were huge. GPT3 was a big leap from GPT2. GPT4 was a big leap from GPT3.
Then… silence. They hit the kink of the curve. GPT5 was delayed. When it came out, it wasn’t the step change we had seen before.
Meta-analysis show that overall, model capability looks to scale logarithmically with training resources and thinking time.[1] The graphs are a little confusing for the non mathematical - they use something called a log scale that makes things look like they’re growing exponentially bigger or smaller than they really are. Here we’re making the growth in capabilities with resource use look exponentially better than it really is, which is a definite chart crime because it gets shared around without context and nontechnical people interpret it incorrectly.
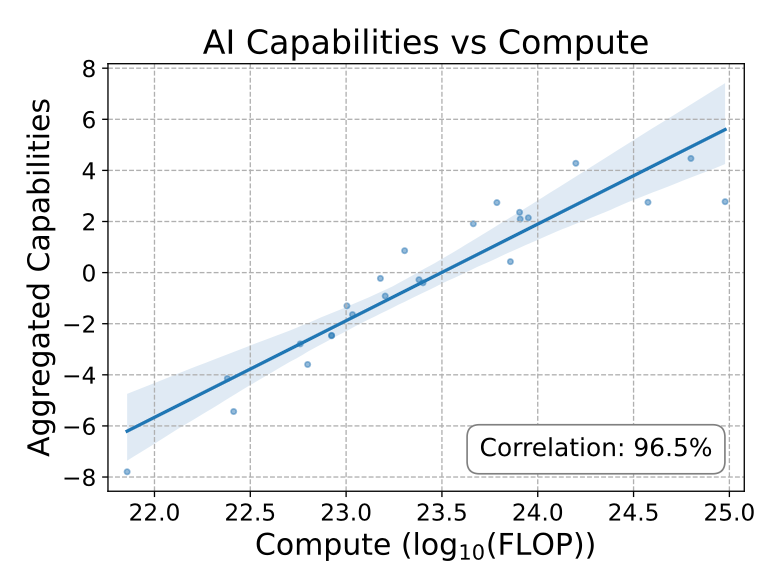
Moore’s law does mean that we get exponentially more computing power over time, which offsets this diminishing returns to a certain extent. However, we don’t also have exponentially growing high quality data over time (there’s only one internet), and research shows you must scale both in tandem to get good returns. 4
The gains from scaling were a one off win. Since the original 2024 GPT5 failed (and was renamed 4.5), we have been transitioning out of the scaling era, and into the post-training era. Companies hope they can use intelligent fine tuning methods to get more juice out of the models after they have trained them. This shift in focus gave us last year’s breakthrough, reasoning models.
Reasoning Models and Post-Training Advances
Reasoning models take advantage of a new post-training technique; they are trained from a base model to produce a "chain of thought"(COT) or a series of reasoning steps before they answer a question.
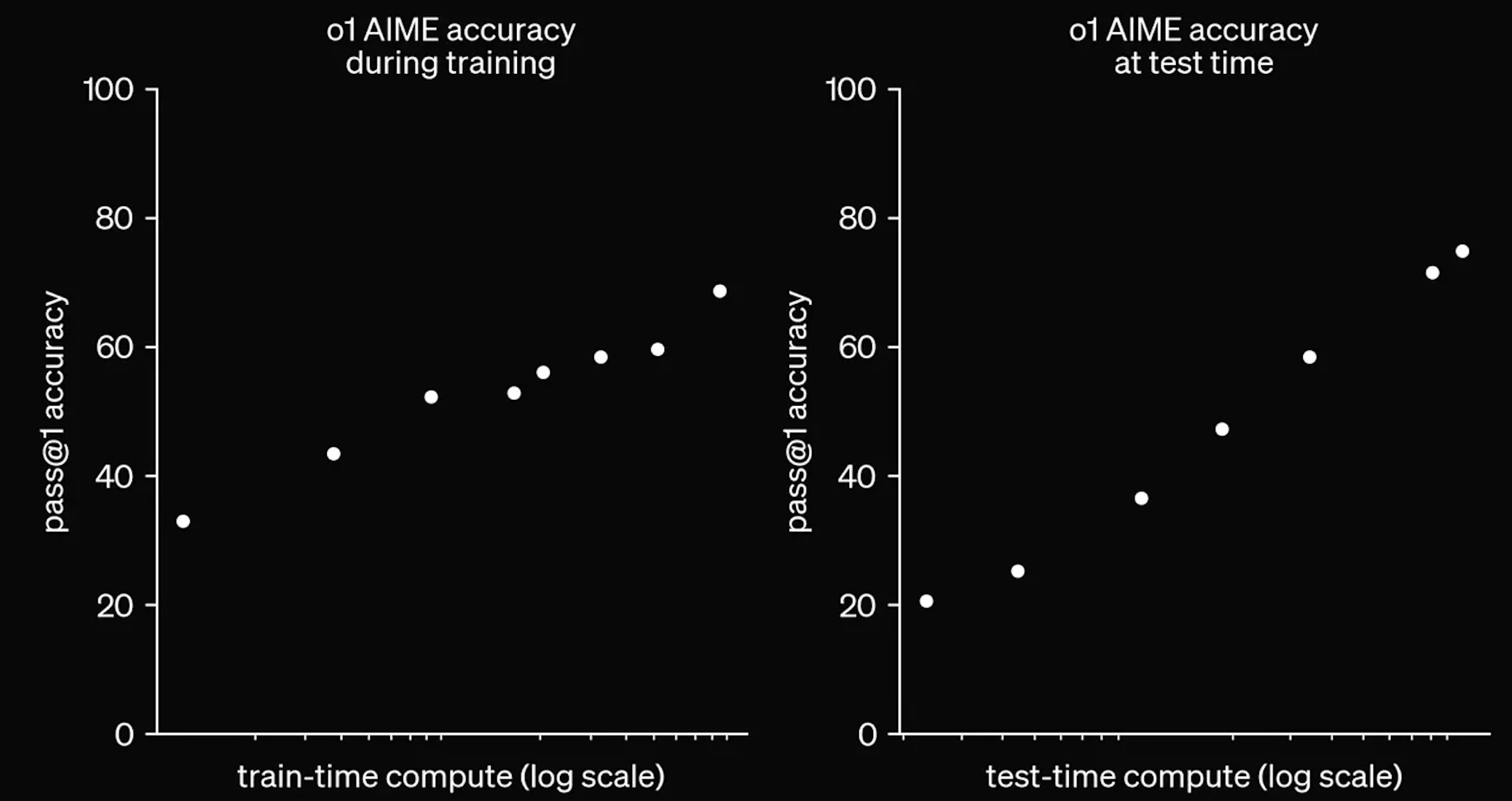
Reinforcement Learning methods are used to improve the quality of the step by step reasoning. The model learns to copy high quality COTs that lead to correct answers, from sources such as textbooks. The model receives intermittent rewards as it reaches milestones in its working out. And at the end, you reward the model for having a correct answer. We can also scale up compute to search for better answers at inference time. Models can increase thinking length to get the best answer, or choose the best answer from multiple thinking simulations.
The type of post-training scaling we see with reasoning models seems particularly effective in verifiable domains like math and coding. The fact the answer is verifiable lets us generate lots of sample problems to train the model. These are also domains in which humans naturally think step by step, so it makes sense that a chain of thought helps.
This can lead to very impressive results; an advanced version of Google's Gemini model was able to achieve a gold medal in the international mathematical olympiad, a math competition for the world's smartest high school students. Importantly, it did it all in natural language, with no computer algebra system.
Unfortunately, post-training methods are a poor substitute for the easy gains of the pre-training era. Instead of becoming dramatically better at many things with no algorithmic improvements necessary, post-training improvements are a hard slog. You must invest heavily in RnD to improve models on specific tasks like coding. And we still see the diminishing returns from resource investment we saw with post-training.
The Bubble
If we then take this recent slowdown and think about its economic implications it gets grim. Labs have implicitly made a massive financial bet on continued improvements. This year, investment in AI datacentres is 1.2% of US GDP, higher than investment at the height of the dot-com bubble,5 or even government investment in the Manhattan project, which consumed only 0.4% of US GDP. The US economy is essentially experiencing a private sector stimulus from companies investing in datacentre buildout.
The Magnificent 7 stocks - NVIDIA, Microsoft, Alphabet (Google), Apple, Meta, Tesla and Amazon - make up around 35% of the value of the US stock market. By the end of 2025, Meta, Amazon, Microsoft, Google and Tesla will have spent over $560 billion on AI in the last two years, with profits of only $35 billion. NVIDIA is an outlier; they have a profitable business model selling shovels in a gold rush.
Take one example; Meta. Meta's AI spend on datacentres in 2025 was more than 70 billion USD. It has also been handing out huge NBA max contracts to top AI researchers, spending hundreds of millions of dollars to acquire them from competitors like openAI. It only made about 2-3 billion this year from genAI. It's LLMs are peripheral to its business model; it makes money by getting people to watch short videos so it can target advertisements at them. If we live in a future where AI progress stagnates, this sort of investment could be the second worst financial decision Mark Zuckerberg has ever made (the metaverse is still worse).

OpenAI is also losing money. Sam Altman thinks it is worth it; "As long as we're on this very distinct curve of the model getting better and better, I think the rational thing to do is to just be willing to run the loss for quite a while"6. But what if the models stop getting better?
A large part of the US stock market's growth is built on a chain of AI investment. Chip manufacturers like NVIDIA make GPUs. Hyper-scalars like Microsoft and Amazon expand compute availability by buying those GPUs. OpenAI, Anthropic, Meta spend money on compute, using it to train new models and then serve them. Consumer products are made using those AI models, like ChatGPT, or AI coding tools. People buy those consumer products.
If progress stalls, there is a inverse chain of negative effects that end up with a strong market correction.
Diminishing returns will lead to a narrowing of the gap between leading developers and open source offerings. Profits fall, as the landscape becomes more competitive and margins shrink. Companies will have expended massive resources on stranded assets; GPUs are perishable goods, they become outdated fast. Companies are now massively in the red with falling profits. Hyperscalars will stop datacentre buildout. Chip manufacturers slow down. The bubble finally bursts; the market will then contract as everyone in the whole chain takes losses.
This isn’t to say that AI won’t be massively transformative. Internet technology had a bubble, and then went on to dominates our lives and make the biggest companies in the world. I believe this is the pattern we will see in the near future with AI. If we get a reprieve, we need to use this time productively to set up governance structures and institutions so that we are prepared when seriously powerful AI actually arrives.
https://paulkedrosky.com/honey-ai-capex-ate-the-economy/
https://www.cnbc.com/2025/08/08/chatgpt-gpt-5-openai-altman-loss.html